Session management is always a pain in the ass for the programmers.
Is never the case to say that it is easy.
With the introduction of the technology up to here spoken in this blog (EJB), we have a new way to manage user' session.
Let's see how.
This practice will work both in the case you want to develop a web application that uses a EJB as logic tier and in case you have a desktop application that uses the logic tier as business tier.
The trick consist in use a stateful session bean in order to keep active the session.
Is never the case to say that it is easy.
With the introduction of the technology up to here spoken in this blog (EJB), we have a new way to manage user' session.
Let's see how.
This practice will work both in the case you want to develop a web application that uses a EJB as logic tier and in case you have a desktop application that uses the logic tier as business tier.
The trick consist in use a stateful session bean in order to keep active the session.
@Stateful(name="Login")
@Remote(IUser.class)
//@StatefulTimeout(value = 10, unit = TimeUnit.SECONDS)
@StatefulTimeout(value = 2, unit = TimeUnit.HOURS)
public class LoginManager
implements IUser {
private static Logger logger = Logger.getLogger(LoginManager.class);
private Integer IdUtente;
....
....
@Remove
public void doLogout() {
logger.info("distruggo la sessione e rimuovo l'EJB");
this.IdUtente = null;
}
@PreDestroy
private void myPreDestroy(){
logger.info("PREDESTROY invalido la sessione e distruggo il bean");
this.IdUtente = null;
}
....
}
The method doLogin(String user, String password) is omitted because irrelevant for this scope.In order to understand the trick, let's analyze the code from the top.
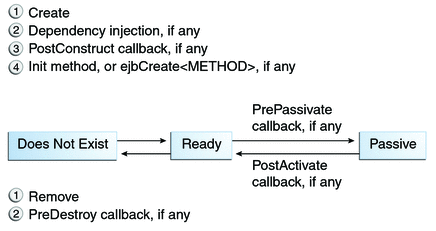
Stateful session beans, so the EJB container will handle itself the question to manage the user session.
Remote, needed because we want to expose this methods via the public interface IUser.
Statefultimeout is used to keep active for a certain defined time the EJB. After this time is triggered, the ejb container (jboss/glassfish/whatever) will handle to remove the ejb.
Exaclty: the ejb will be removed, thus the user session will be invalidated.
Let's see the
- @remove notation. Indicates that the stateful session bean is to be removed by the container after completion of the method.
- @predestroy notation. Goes hand in hand with remove, when the method marked with remove completes, the EJB container will invoke the method annotated with the @javax.annotation.PreDestroy annotation, if any, and then destroy the stateful session bean.
Remove is used to "remove" the bean after the method doLogout is called.
Predestroy is used to invalidate the session, when the timer triggers the end of the session. Infact no one will call the doLogout method, but we want to invalidate anyhow the session.
Of couse the invalidation here means just put a variable to null, but you may want to perform more complicated actions.
On the client side the session is maintained just keeping the pointer to the ejb handler. If the ejb has been removed on server side, using the stored handler will result in an exception. Thus the programmer will understand that the session is no more valid.
sources: